

Under new management: tips for taking ownership of a long-running data project
By Thomas 'Richie' Richardson on April 14, 2022As data scientists, we should be ready and able to join a project, understand it and take ownership over it as the primary data scientist.
But what if the project is big, and long-running? What if you’re faced with a GitHub repo that is several years old, and has been worked on by half a dozen data scientists? How can you master it all and make that project your own?
This is something I’ve been grappling with for the past six months, and I wanted to share what I’ve learned from the process. Here are my tips for anyone facing a similar challenge…
1. It’s OK to be a bit daunted at first
The project I came onto was fairly large for a single person; several ML models, solving non-standard problems. These models used multiple datasets that came from several sources, and each had multistep workflows that cleaned and enriched them. This isn’t my first rodeo, but I was overwhelmed at first! If you’re feeling the same way, know that this is natural. This feeling will pass, as you gain mastery and see how all the pieces fit together. Give it some time.
2. Start at the highest level and work down
For me, this meant starting with the main model and the API the customers used to call it. Once I understood how the model made predictions, I moved onto the model features and how they were engineered. Then, onto the data used to train the model and how it was cleaned, and so on. This stops you getting bogged down in technical details too early on. It focuses you on the part that directly provides value, and allows commercial users to make great decisions.
3. Focus on the parts of the code most critical to you
Why were you brought onto this project? I was assigned to this project because the user wanted to improve the model’s performance. So for me, understanding the model features was a great place to start in getting to grips with the project’s codebase. On the other hand, it was only later that I looked at details that were not directly relevant to my job, like how they unified data from several different sources. This will let you hit the ground running and start making progress with the project, even if you haven’t learned the ins and outs of all the codebase.
4. Make sure your to-do list is up to the task
Imagine this scenario: you’re trying to understand the codebase of a project. You start with engineer_features.py. It takes dataset A as an input and results in dataset B, so you make a note to investigate how dataset A was made. Dataset B is saved using an internal function rather than a widely used library for saving data.
The code for this function is stored in another repo. So you make a note to check out that repo and figure out why standard libraries were not up to the task. But back to the script: it calls six functions. Some are stored in feature_engineering_utils.py, so you make a note to check that out, but others are in another folder because they’re used by another script, so you make another note and…you run out of sticky notes!
In situations like this, you’re going to need a good to-do list or task management system to handle it all. At the very least, you should be able to easily add new tasks and rearrange them to prioritize. Seeing what tasks you ticked off yesterday or last week can be useful too (for those “did I already check this script?” moments!)
I use Todoist for solo work and Asana for team projects, but there are tons of tools out there. If anything slips through the cracks, you might set yourself up for embarrassment later. You might just argue confidently to the customer that a feature isn’t in the model, when it definitely is. I neither confirm nor deny that this happened to me.

5. Look to your ancestors for guidance
Identify all the people who worked on the project before you, and figure out if they can be contacted for help (they may have left the company.) Some of Peak’s most senior data scientists had worked on my project and, luckily for me, most were still easily found in our clubhouse.
Even more luckily, they are incredibly nice and were patient enough to answer my questions and occasionally hop on a call with me, so we could dig through code together. However, I also found that one of the key data scientists who worked on the project was leaving in a few weeks, so I had to move fast to pick their brains as much as I could before that happened!
? Top tip for finding these people: if your project uses version control like GitHub, look at all the unique contributors to the project repo. This can allow you to identify people who might have joined the project for only a few weeks to deploy their expertise, who may still be good sources of knowledge.
6. Get graphical
To get a big picture view, I made a diagram showing how the various scripts related to each other. Script A creates a dataset that is fed into script B, which gets cleaned and builds a model, which is stored in an s3 bucket which can be found folder1/folder2/here, etc. I did it ‘old school’ – on paper with a pencil – but any tool will do. Seeing how things fit together in a visual way is extremely useful.
If you ever made ‘mind maps’ to revise during your school years, you’ll also know this can help you to memorize large amounts of information. If you’re like me, be prepared to go through multiple iterations of this graph as your knowledge of the project builds. Looking back on the multiple versions of the graph brings a real sense of accomplishment, as you can literally watch your mastery of the project grow.
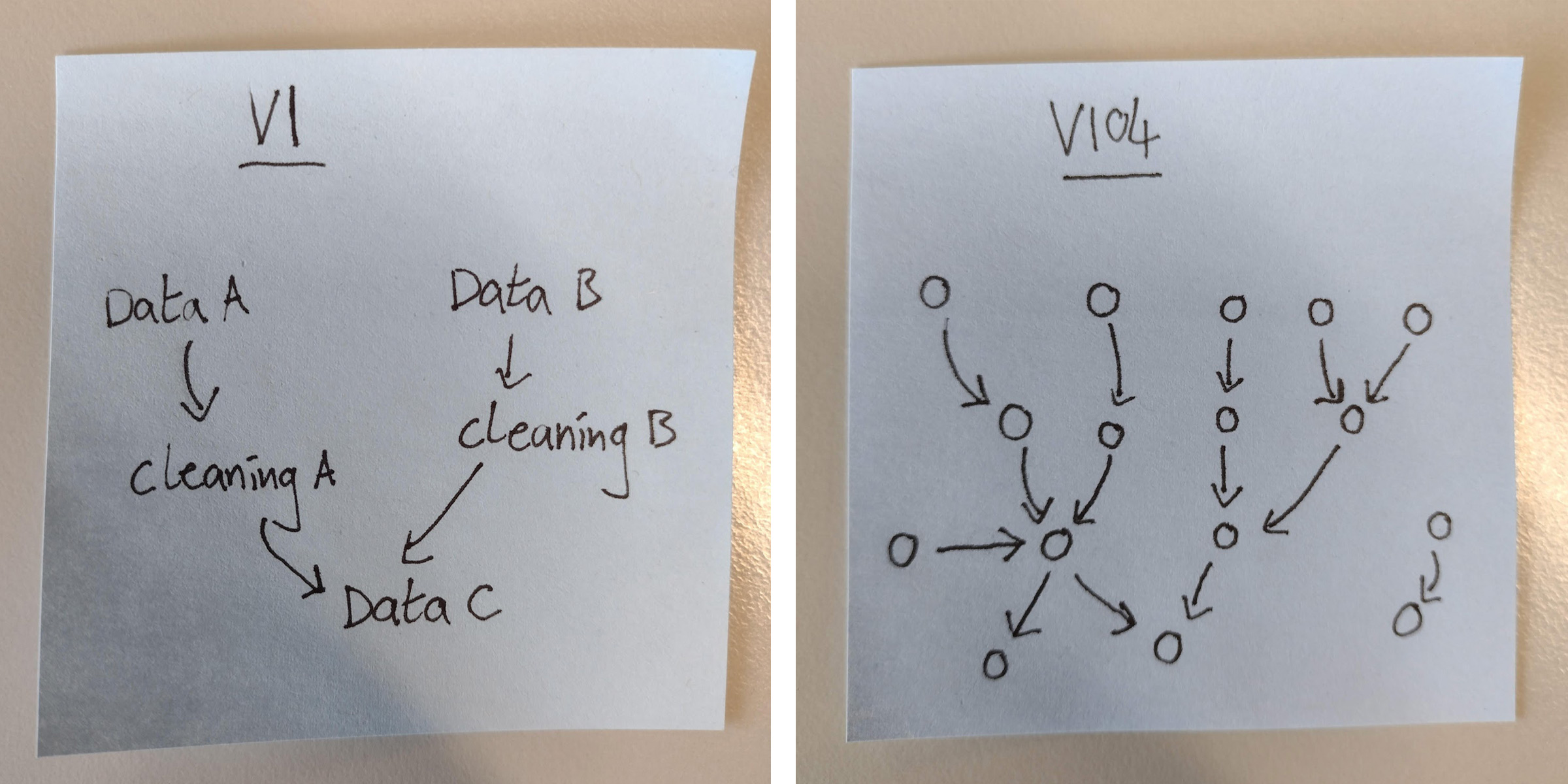
How it started vs. how it’s going (Image credit: I literally drew them myself ?)
7. Think long and hard about rewriting large chunks of code from scratch
Some scripts and workflows on the project looked so messy I felt an urge to “burn it all down and start again.”. You may know this urge. Why spend hours understanding the specific way this was implemented when you could write it yourself from scratch in a similar amount of time?
RESIST THIS URGE. I reminded myself that this code has been running successfully in production for years, so it surely can’t be as bad as I thought it was. Smart people built this. Over those years, many bugs have been fixed, and all the possible edge cases have come up and been addressed.
When you think about it, it would be extremely arrogant of me to think that I could rewrite the code from scratch and write it perfectly the first time. Most bugs and edge cases simply cannot be predicted when we first write code. They only come to light as the code is battle-tested in production.
I’m not saying you never change long-running code; but you should nearly always refactor existing code, piece by piece, rather than rewriting from scratch. The code from my project is littered with features that are no longer in use, and many functions have arguments that are seemingly never used.
Sometimes I have stripped this code out, but only after being absolutely sure that they truly are no longer in use! Again, it’s good to make use of GitHub or whatever you’re using for version control. Before refactoring a function, I’ll search for all the scripts where that function is called to really get a feel for what can be changed and what really should be left alone.
Most bugs and edge cases simply cannot be predicted when we first write code. They only come to light as the code is battle-tested in production.
Thomas Richardson
Data Scientist at Peak
8. Leave the project better than you found it
Finally, you weren’t the first data scientist to work on this project, and you probably won’t be the last. Give some thought for what the next data scientist will inherit from you, and prepare accordingly. When you leave the project, ideally the code and repo should be cleaner than when you started, and the docs more fleshed out.
You may have even written more tests. If you’ve joined a project that is a big mess of years of code, don’t repeat the mistakes of your ancestors. Leave the project better than you found it, so that in generations to come, data scientists won’t have to read this blog post; they can just get to work!
Join Peak's data community
The Peak community exists to support data scientists and analysts who want to make a difference and drive change within their organizations. Get involved!
More from the Peak data science team

How to leave academia and get a data science job

Storytelling with data, part 2 – Visualization best practice
