

A look under the hood of Co:Driver, Peak’s new generative AI product
By Ninad Kulkarni on October 16, 2023 - 10 Minute ReadPeak recently unveiled its new generative AI product, Co:Driver. This exciting product is intended to bring a new level of interaction between business users and their data.
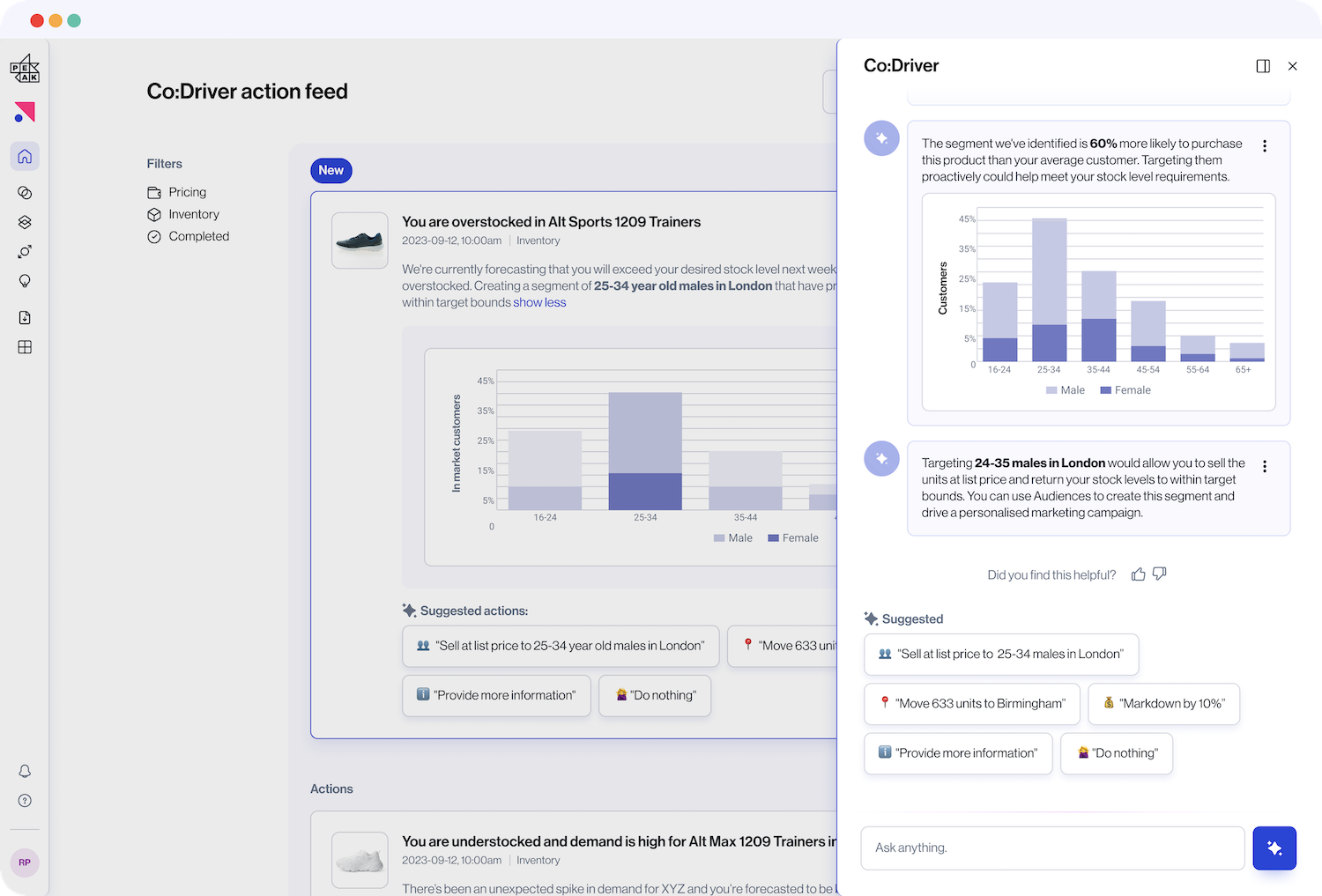
Co:Driver combines fine-tuning a large language model (LLM) with a user’s existing AI applications and business data. Co:Driver continuously searches for information, efficiencies, opportunities and anomalies of potential interest to the user. These are surfaced as bite-sized contextual recommendations, with the user able to choose their preferred next step from a number of AI-generated actions.
Using outputs from a user’s existing AI applications on the Peak platform, Co:Driver also allows users to ask questions about their business in natural language, making the AI even more explainable.
This development represents a new approach to using foundational LLM models in business, one which focuses much more on delivering tangible business value through actionable recommendations, rather than creative responses to prompts. The combination of natural language generative AI and Peak’s predictive AI applications will redefine the use of AI in business.
We are incredibly excited about Co:Driver and the potential it has to fundamentally transform how people interact with technology. This article will cover some of the fundamental technical concepts we have used in development.
Part one: finding opportunities with agents
To date, most generative AI use cases focus on generating new content in response to a user request, often in a chat interface. Many people will be familiar with the dazzling images generated by Midjourney, the ability of ChatGPT to generate the answers to secondary school homework assignments, or a chatbot’s ability to answer customer service queries. But what if you don’t know the question to ask? What if there’s a story hidden in your data that you didn’t know to look for?
That’s the reason we’re using autonomous agents, which are software programs that can work independently from direct instruction by the user. Agents can be programmed to carry out specific tasks, such as looking for specific patterns or text. In the case of Co:Driver we have created agents that continuously query the data from Peak’s business applications looking for opportunities of interest. The agents in Co:Driver are programmed with the unique business objectives of the customer and an understanding of the data schema, so that they can get to work quickly and effectively.
The agents in Co:Driver are programmed with the unique business objectives of the customer and an understanding of the data schema so that they can get to work quickly and effectively.
Ninad Kulkarni
Engineering Manager at Peak
Part two: Fine-tuning with embeddings and adapter layers
A large language model is a trained deep learning model that understands and generates text in a human-like fashion; we have chosen Google’s PaLM 2 LLM for Co:Driver.
Some LLMs typically lack context which can lead to hallucinations when asked domain or company-specific questions. Fine-tuning is the process of giving an LLM context about a specific domain where you want it to operate.
There is a common misconception that fine-tuning requires the foundational LLM to be duplicated, modified to include business context and then hosted separately from the original. This is both computationally complex and prohibitively expensive — and, fortunately, not necessary.
A superior approach is to use a combination of embeddings and an adapter layer. Embeddings involve assigning numerical values to text strings so that they can be more easily compared by a machine. Peak is using embeddings to codify instructions and underlying data which gives the LLM a strong semantic understanding of the specific business domain it is operating in. For each new customer that uses Co:Driver, embeddings will be created that include the data model, schema, key operating model parameters and business logic.
An adapter layer is a further means of fine-tuning an LLM. Think of an adapter layer as a mini-LLM or a subset of the foundational LLM. Typically much smaller than the foundational LLM, it is much less computationally intensive to train than retraining the LLM as a whole. Adapter layers can be created for each Peak customer to provide even greater detail about the specific business and assist with task-specific operations.
It’s worth noting here that the foundational publicly-available LLM is never re-trained using proprietary customer data and customer data is never stored in the foundational LLM.
Prompts are how instructions and requests are passed to the foundational LLM model. Prompts can be entered by a user manually or they can be generated by software. In the case of Co:Driver, agents generate the prompts based on the opportunities and insights they have found in the data. Thanks to the embeddings and adapter layers, the prompts generate outputs from the LLM that are highly relevant, contextual and actionable. In a way, the LLM helps make sense of the large volume of data the agents are reviewing.
Part three: Increasing accuracy with retrieval-augmented generation
Hallucinations are an important matter to address when doing any work in AI. A hallucination occurs when a model provides a response that is incorrect and not justified by its training data. When applying AI in business, hallucinations must be all but eliminated to avoid the risk that a business leader makes a decision that could negatively impact operations or business performance.
With Co:Driver, we are using Retrieval-Augmented Generation (RAG) to avoid hallucinations. RAG is a framework consisting of input templates and output parsers that process and assess the reliability of all potential outputs. If an output does not bear sufficient similarity to the embeddings, the RAG framework will discard the output or send it for recalculation. Our guiding principle is that the system will choose not to answer rather than provide a low confidence result.
One of the biggest strengths of using foundational models is their ability to work with unstructured data. If a prompt is sufficiently preceded by appropriate documents, it becomes possible to ensure the responses are within specific guard-rails. Co:Driver’s RAG framework does exactly that by using a combination of embeddings and adapter fine-tuning that gives the model complete and updated information to generate the best possible response.
Our guiding principle is that the system will choose not to answer rather than provide a low confidence result.
Ninad Kulkarni
Engineering Manager at Peak
Part four: Protecting data with virtual private cloud peering
Information security is always a priority at Peak and we have architected Co:Driver in such a way as to maintain the integrity of customer data at all times. All customer data remains stored in its normal secure location, either in its tenant on the Peak platform or in the customer’s own data lake or warehouse.
We use Virtual Private Cloud (VPC) peering networks to encrypt data transmissions between Peak and Google. A VPC peering network is an encrypted and secure connection that can exchange data between two clouds. Data is also encrypted using TLS. In all cases, data transmission and storage will be GDPR compliant.
A new paradigm for AI
Up to now, discussions about different types of AI typically delineate between predictive AI (the use of machine learning and statistical algorithms for predictions) and generative AI (learns the patterns and structure of input data to generate new data that has similar characteristics). Often these are presented side by side, as if the two shall never meet. In reality, to get the most value for business they have to work together.
By combining the power of Peak’s predictive AI applications and this new generative AI capability, Co:Driver delivers a powerful new interaction layer between users and their data. This approach will become transformational in its ability to direct business teams on where to focus their efforts, thereby improving decision making, boosting efficiency and delivering higher ROI.
We are actively recruiting customers to join the Co:Driver private preview in early 2024 — join us to help build this amazing technology.
Register your interest in the Co:Driver private preview
Fill in your details if you're interested in learning more about our new generative AI product.
More from Peak

Peak launches new generative AI product, Co:Driver, powered by Google Cloud and its PaLM 2 Model
AI Benchmarking report
