Kick-starting a data science project with Peak
By Vanessa Virgo on May 7, 2021 - 5 Minute ReadAs a data scientist, there are many different types of decisions we need to make along the way. Two of the key ones are around how we get the data we need in a good format to model on – and how do we use this data in the first place!
With the help of Peak’s Decision Intelligence platform this can be done without needing to set up things on your local machine. In this blog, I talk a bit about Peak’s ability to ingest data, how it can help the data scientist analyze the data they will be working with, and – finally – how it enables us to take the transformations as re-runnable scripts, ready for some modelling.
Ingesting data
One of the first things I think about when starting a data science project is how will I get this data? When working with different types of data, coming from multiple sources, it can often be difficult to get it into one place.
However, with Peak, I’m able to set up handy data feeds which allow the customers I work with to send me their data safely – or, I can connect to their databases to retrieve the data myself. Normally I’d need to wait for another team to get me the data before I can start investigating it. With Peak, I’m able to do it myself, allowing me to spend more time on the bits of data science that I enjoy!
Here’s a look at the different types of data feeds that we work with:
Database connector
- This data feed connects directly to the database source, so that you can pull data from the database straight into one of Peak’s clusters
SaaS connector
- This data feed can pull data from different software sources, such as Google Big Query or Facebook Ads
- This means we can collect web-based data to help our modelling later on in the project
API connectors
- This data feed allows for data to be sent directly into a database, in the form of json!
- This means that, if we want live data, we can easily ingest it and use it 24/7
Direct
- This data feed allows direct uploads to Peak; this can be automated, depending on how our customer’s system is set up
- The data that is sent can be stored in Peak’s datalake, or saved onto our Redshift Clusters – which means we can quickly access it using PostgreSQL
These feeds do work slightly differently from each other in terms of the way they interact with each of the different services. For example, a direct upload is very different from directly connecting up to a database – it doesn’t need to have the same permissions as an upload. However, as it can all be done easily through Peak, it means the data scientist doesn’t need to think about it too much!
Normally, a data scientist would have to create these manually. This, of course, would be time-consuming – meaning data scientists spend less time doing the more exciting parts of data science! One of the advantages of using Peak to ingest data is being able to interact with different types of data, regardless of how they’re set up.
With Peak, I'm able to do it myself, allowing me to spend more time on the bits of data science that I enjoy!
Vanessa Virgo
Data Scientist, Peak
Analyzing the data
Performing initial analysis can take time, especially if you have to create a place to comfortably investigate the data you’re working with. That’s why at Peak we have workspaces built on Peak. These are places where we can investigate the data we have, using either R or Python. Plus, as the data is already connected in the backend, I don’t need to worry about having to find a way to get the new data in – it’s just there!
Peak has the flexibility to create several different types of workspaces, which – depending on your needs – can be created at different sizes. Plus, as they’re all brand new when they’re set up, you can easily include all the packages you need without the hassle of setting it up on your own machine (which, once again, takes time away from doing actual data science!)
There are several types of initial analysis you need to do when first starting a data science project. Using Peak, I would usually create an R or Python workspace and start digging into the data, possibly starting with:
- Checking for NULLs
- What are the distributions of certain fields?
- Can we aggregate the data for the model?
- Plotting the data (bar charts are always a good place to start!)
Using Peak’s workspaces, we can do this easily and at speed as the workspaces are run on their own clusters! All we need to do is fetch the data from wherever the data is stored and run the analysis.
Transformations
Now that we know what our data looks like, it’s time to get some scripts running to transform the data, and get ready to start creating some models! Normally, to create re-runnable scripts, we need to set up a place for the jobs to run – which causes even more time to be taken away from us! With Peak, we have workflows which takes the job of creating a place to run the scripts off us.
Workflows have the ability to run scripts and even join different types of scripts together to run as one job. This is great if (like me) you create different scripts in R, Python and SQL to transform the data. Plus, if they need to be run in parallel, workflows give you the ability to do this.
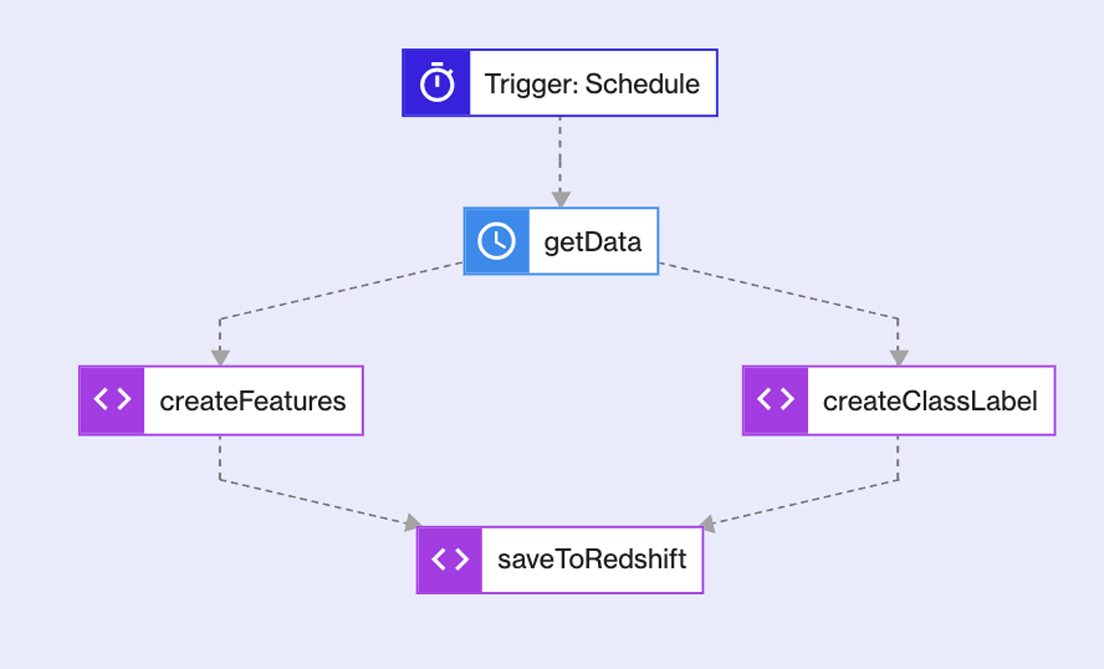
In this example, I have four scripts that need running, two in parallel. With workflows, they can be easily connected, and each runs when I need it to run! The workflow is activated by a trigger, which is either time-based or action-based.
In this case, the trigger is time-based, so it runs on a schedule at the same time, everyday. However, it could be an API (action-based) trigger instead. Imagine if data was ingested at different times of the day, but we need to wait for it all to be ingested – with an API trigger, it can wait until the data is ingested before starting the transformation. This means that the scripts run exactly when I want them to.
Starting a data science project with Peak
Peak helps as a starting place to get your data science project off the ground! The initial steps of creating a viable model can all be done on Peak, with little interaction with any backend processes. Not only does this save me time as a data scientist, but it means I don’t need to worry about how it works – just that it does, and that I can focus on the most interesting parts of data science!
Like the sound of Peak?
Get in touch with our team to discover the opportunities it could carry for your business.
More on our platform

Connecting your data in the Decision Intelligence era

Decision Intelligence is here